学习参考:
PyTorch简单入门视频
深入浅出PyTorch
小土堆笔记
前置知识
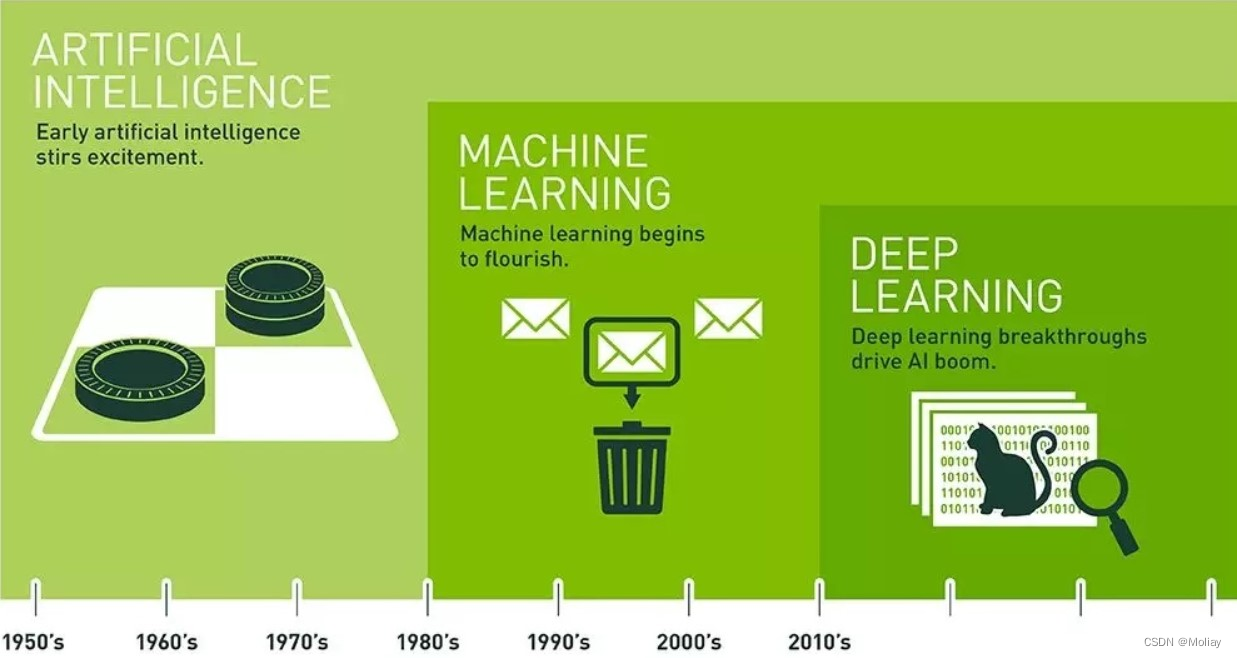
- AI vs ML vs DL
- AI(Artificial Intelligence):通过让机器模仿人类进而超越人类
- ML(Machine Learning):让机器模仿人类的一种方法
是AI的一个分支(也是最重要分支) - DL(Deep Learning):让机器不借助人工标注,也能自主提取目标特征进而解决问题的一种方法
是ML的一个分支
TP为True Positive,True代表实际和预测相同,Positive代表预测为正样本。
同理可得,False Positive (FP)代表的是实际类别和预测类标不同,并且预测类别为正样本,实际类别为负样本;
False Negative (FN)代表的是实际类别和预测类标不同,并且预测类别为负样本,实际类别为正样本;
True Negative (TN)代表的是实际类别和预测类标相同,预测类别和实际类别均为负样本。
-
模型评价指标
-
Overall Accuracy:所有预测正确的样本占所有预测样本总数的比例
-
Average accuracy( AA) :平均精度的计算,平均精度计算的是每一类预测正确的样本与该类总体数量之间的比值,最终再取每一类的精度的平均值
-
Recall:也称召回率,代表了实际为正样本并且也被正确识别为正样本的数量占样本中所有为正样本的比例。
Recall是判断模型正确识别所有正样本的能力。 -
Precision:也称精准率,代表的是在全部预测为正的结果中,被预测正确的正样本所占的比例
Precision代表了预测结果中有多少样本是分类正确的。 -
F1:可以解释为召回率R(Recall)和P(精确率)的加权平均。
F1越高,说明模型鲁棒性越好
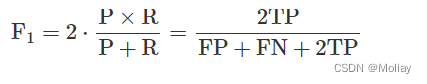
人们希望有一种更加广义的方法定义F-score,希望可以改变P和R的权重,于是人们定义了Fβ,其定义式如下 F β = ( 1 + β 2 ) × P × R ( β 2 × P ) + R \rm{F_{\beta}}=\frac{\left(1+\beta^{2}\right) \times P \times R}{\left(\beta^{2} \times P\right)+R} Fβ=(β2×P)+R(1+β2)×P×R

-
Overall Accuracy:所有预测正确的样本占所有预测样本总数的比例
-
Average accuracy( AA) :平均精度的计算,平均精度计算的是每一类预测正确的样本与该类总体数量之间的比值,最终再取每一类的精度的平均值
-
置信度:在目标检测中,我们通常需要将边界框内物体划分为正样本和负样本。我们使用置信度这个指标来进行划分,当小于置信度设置的阈值判定为负样本(背景),大于置信度设置的阈值判定为正样本
-
-
dir()打开,看见
返回指定对象的属性和方法列表 -
help()使用说明
提供有关对象的详细信息和文档
查看函数不需要括号,可以联想为我们是在求助,而之所以要求助是因为被打劫了,少了东西(括号)~以后用dir()或者help()查函数时,记得无需带最后的括号,因为已经被“打劫”走了
单下划线通常用来表示临时变量、私有变量或函数以及避免命名冲突;双下划线则具有重写Python内置方法、避免命名冲突、名称修饰以及名称修饰器等作用。
一、PyTorch安装
创建虚拟环境
conda create -n 虚拟环境名字 python=版本 -c 镜像地址
清华镜像:https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
北京外国语大学镜像:https://mirrors.bfsu.edu.cn/anaconda/pkgs/main
阿里巴巴镜像:http://mirrors.aliyun.com/anaconda/pkgs/main
出现选择提示,输入y
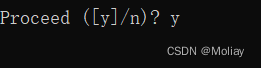
简单验证pytorch是否安装成功
//激活你安装的虚拟环境
conda activate 虚拟环境名
conda env list
conda list
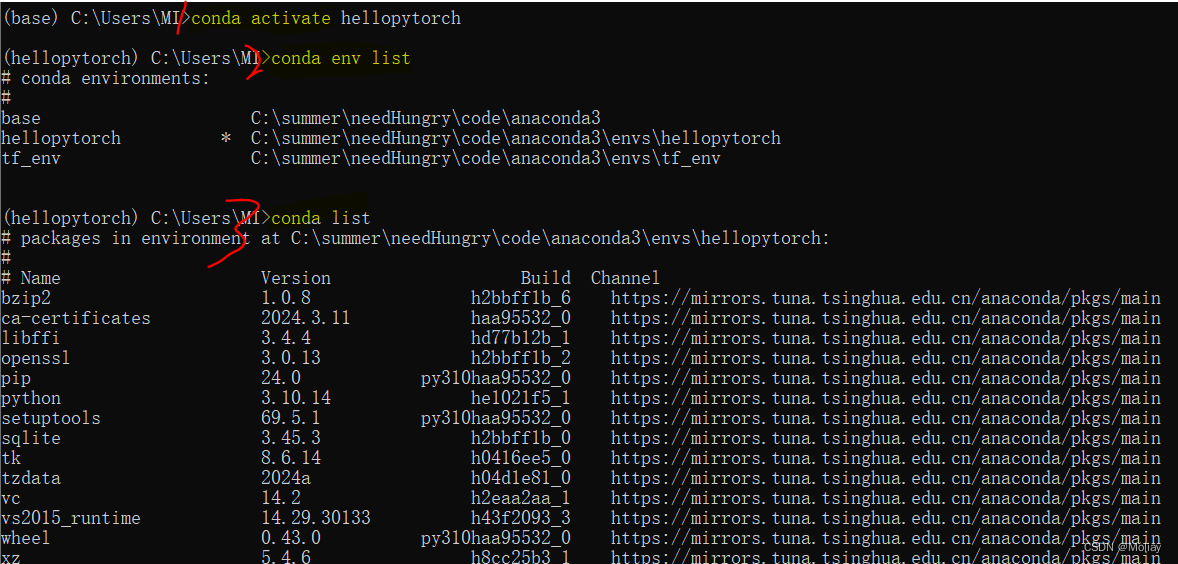
判断CUDA runtime版本
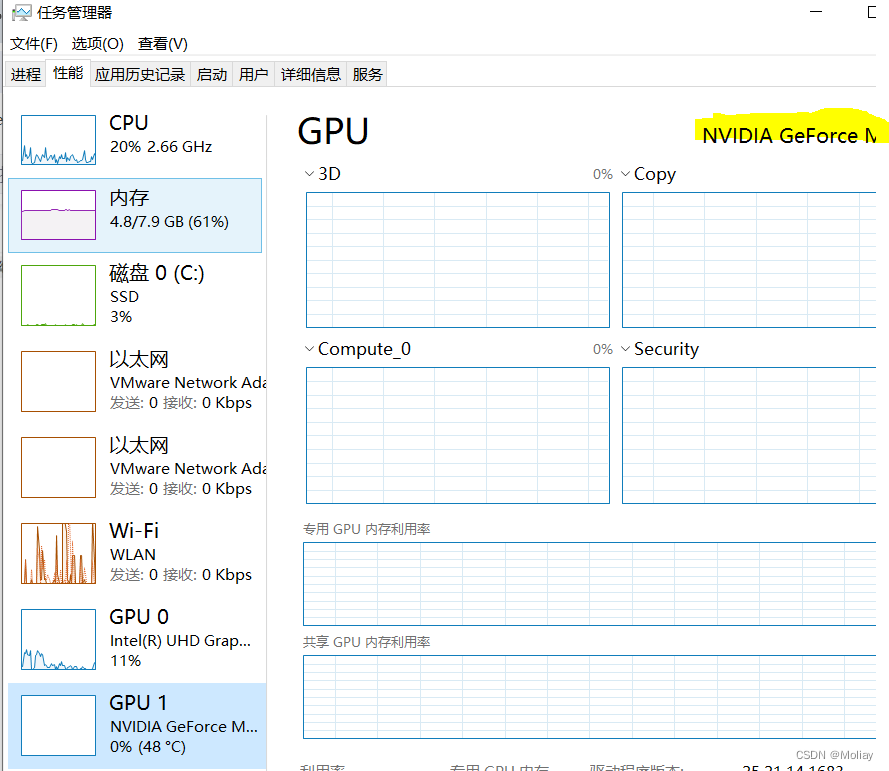
- 更新显卡驱动到最新版本
任务管理器 -》 性能 -》查看GPU型号
https://www.nvidia.cn/Download/index.aspx?lang=zh-cn
在官网选择对应版本并下载,其中台式机选择不带(Notebooks)后缀的,笔记本反之。安装过程中,选择精简版即可,geforce experience可以不选择

-
打开命令窗口(win+r)输入
nvidia-smi来确定cuda driver版本(选择比驱动版本小的 最新版本)
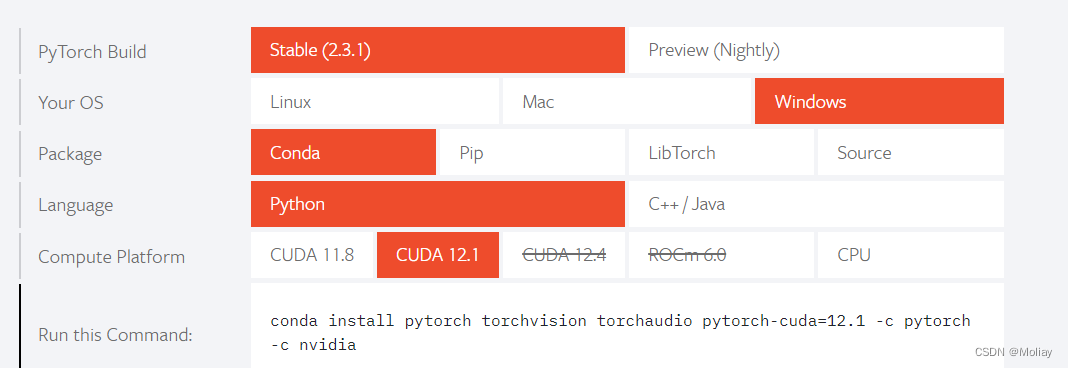
https://pytorch.org/
-
其中,更新驱动程序时,可能进度条会卡着一直不动
- 可以关掉360,火绒,安全管家等
- 或者直接进入安全模式再安装
安装PyTorch
进入之前创建好的虚拟环境中
conda activate 虚拟环境名
从官网找到对应的命令行进行下载
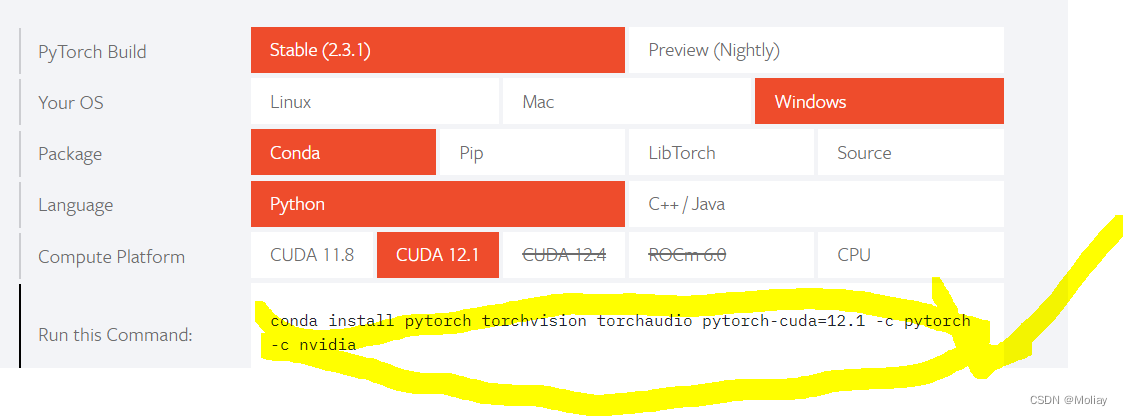
会先罗列将要下载的东西,可以确定下版本是否正确(例如pytorch是否带cuda,python是否是之前指定版本,cuda是否为之前查到的版本);
然后输入y开始下载即可。
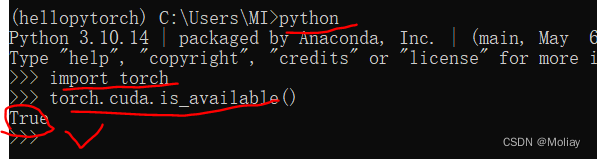
验证PyTorch是否安装成功
激活对应的虚拟环境,输入
conda list
看有木有pytorch或者torch
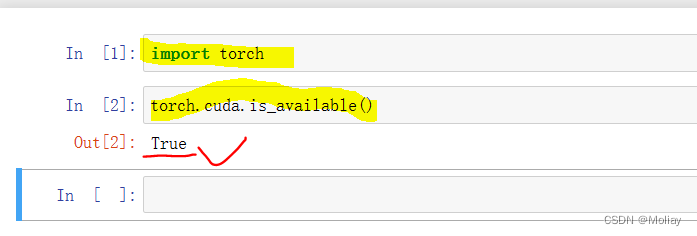
再输入下图中的三条命令,输出true即电脑里有GPU&你的PyTorch也能正常使用你的GPU
二、Jupyter安装
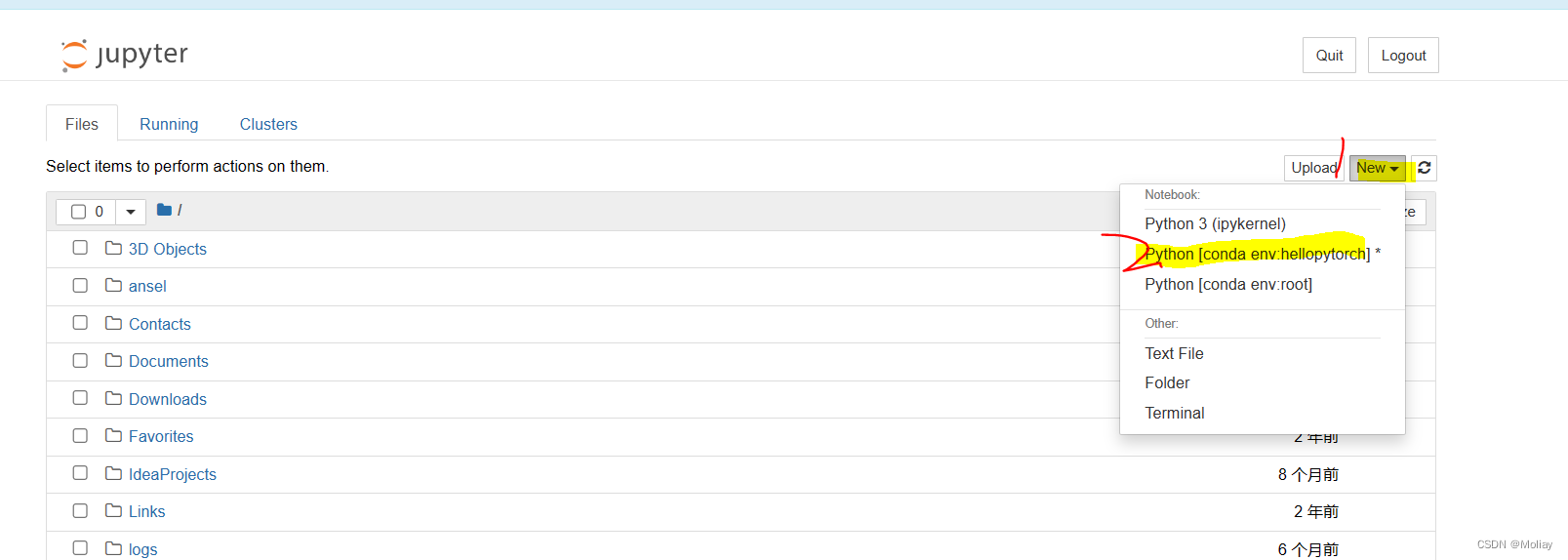
在base里安装pytorch,或者在上述新创建的虚拟环境中安装jupyter,推荐后者
进入虚拟环境
conda activate 虚拟环境名
方法1. 安装 nb_conda_kernels,将所有 conda 环境同步至 Jupyter Notebook
conda install nb_conda_kernels
方法2. 安装 ipykernel,并将指定 conda 环境写入 Jupyter Notebook 的 Kernel
conda install ipykernel
- 验证是否安装成功
输入完一行命令后,shift+回车
看见熟悉的true即为安装成功
- python文件 vs python控制台 vs jupyter
-
python文件
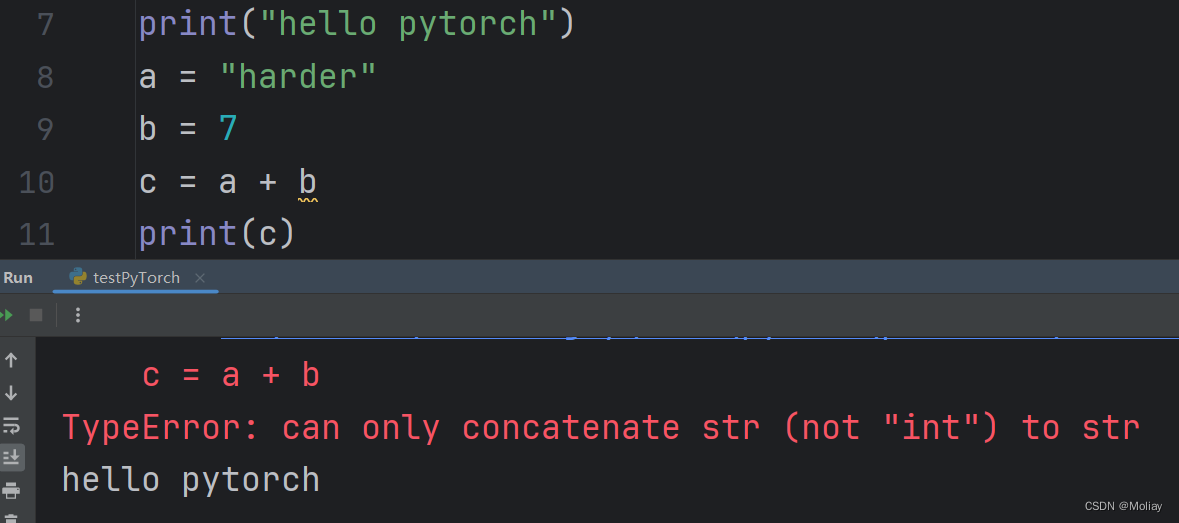
代码以块(python文件的块是所有的行)为整体运行- 优:通用,传播方便,适用于大型项目
- 缺:需要从头运行
-
python控制台
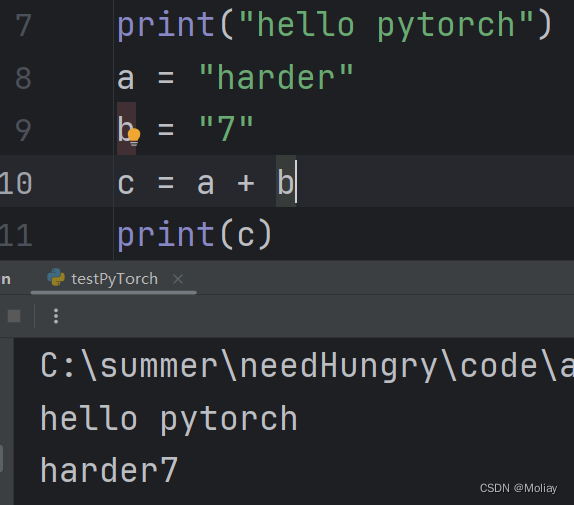
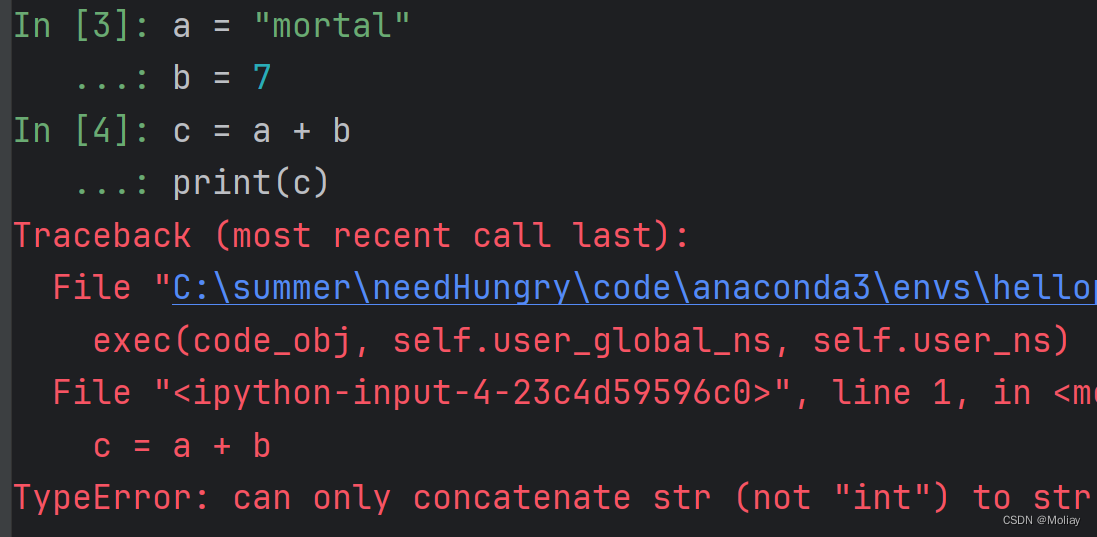
以任意行为块,来运行- 优:显示每个变量属性
- 缺:不利于代码阅读和修改

-
jupyter
以任意行为块,来运行- 优:利于代码阅读及修改
- 缺:环境需要配置
-
三、基础入门
加载数据初识
蚂蚁蜜蜂/练手数据集:链接: https://pan.baidu.com/s/1jZoTmoFzaTLWh4lKBHVbEA 密码: 5suq
Dataset 是一个抽象类,所有数据集都需要继承这个类,所有子类都需要重写 __getitem__ 的方法,这个方法主要是获取每个数据集及其对应 label,还可以重写长度类 __len__
# -*- codeing = utf-8 -*-
# @Time : 2024/6/15 21:39
# @File : read_data.py
# @Software : PyCharm
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
beesData = MyData(root_dir, bees_label_dir)
antsData = MyData(root_dir, ants_label_dir)
trainData = beesData + antsData
当label比较复杂,存储数据比较多时,不可能以文件夹命名的方式,而是以每张图片对应一个txt文件,txt里存储label信息的方式
TensorBoard可视化
- 安装tensorboard
tensorboard不是pytorch自带的,pytorch只提供了使用的接口,所以需要自行下载。
conda install -c conda-forge tensorboard
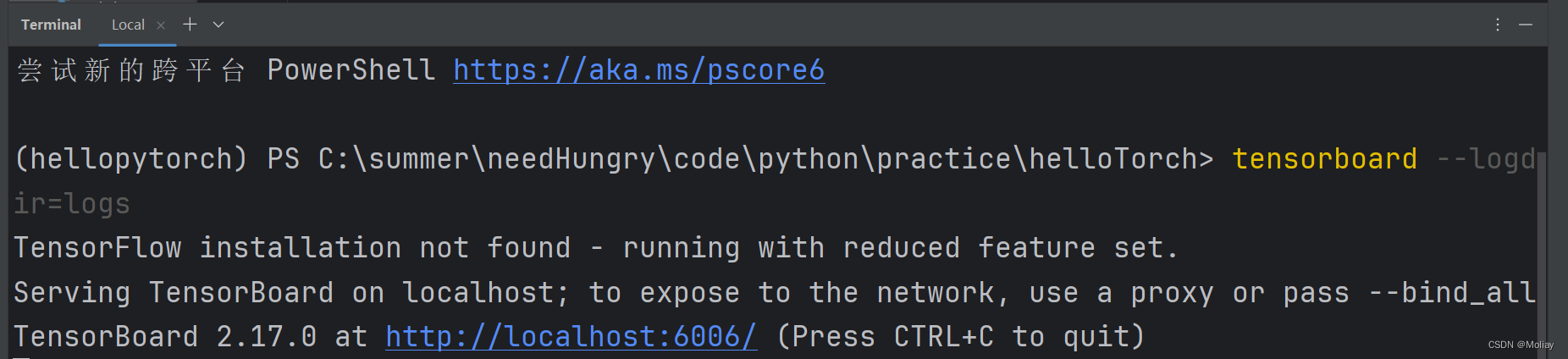
启动tensorboard
tensorboard --logdir=/path/to/logs/ --port=xxxx
logdir=事件文件所在文件夹名
- add_scalar()
# -*- codeing = utf-8 -*-
# @Time : 2024/6/17 11:15
# @Author : Scarlett
# @File : hello_tb.py
# @Software : PyCharm
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')
for i in range(10):
writer.add_scalar("y = 2x", 2*i, i)
writer.close()
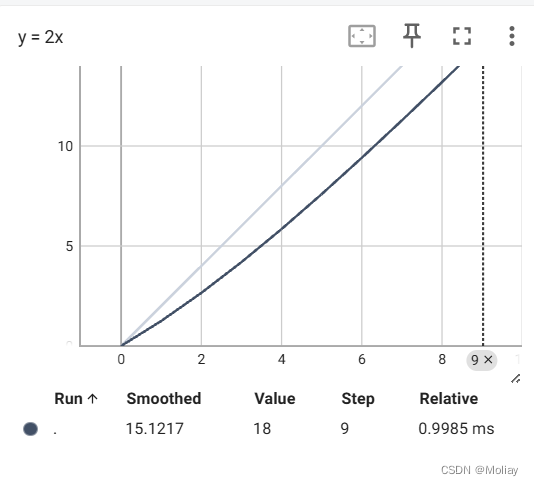
默认端口6006,为了防止端口冲突,也可以指定其他端口
如果想在同一张图中显示多个曲线,则需要分别建立存放子路径(使用SummaryWriter指定路径即可自动创建,但需要在tensorboard运行目录下),同时在add_scalar中修改曲线的标签使其一致即可:
# -*- codeing = utf-8 -*-
# @Time : 2024/6/17 11:15
# @Author : Scarlett
# @File : hello_tb.py
# @Software : PyCharm
from torch.utils.tensorboard import SummaryWriter
writer1 = SummaryWriter('logs/x')
writer2 = SummaryWriter('logs/y')
for i in range(10):
x = i
y = 2*i
writer1.add_scalar("f", x, i)
writer2.add_scalar("f", y, i)
writer1.close()
writer2.close()
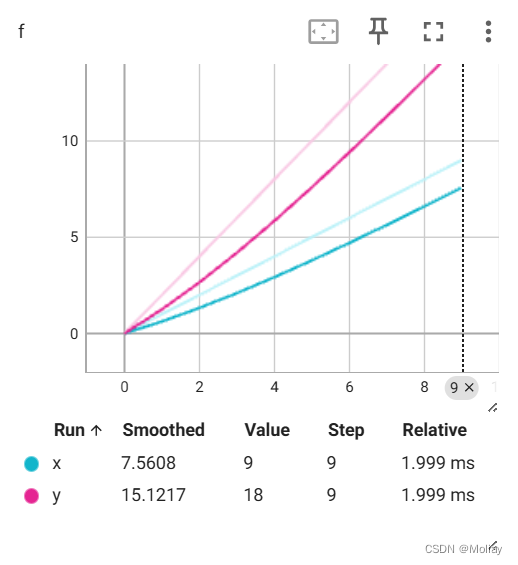
这里也可以用一个writer,但for循环中不断创建SummaryWriter不是一个好选项。此时左下角的Runs部分出现了勾选项,我们可以选择我们想要可视化的曲线。曲线名称对应存放子路径的名称(这里是x和y)。
这部分功能非常适合损失函数的可视化,可以帮助我们更加直观地了解模型的训练情况,从而确定最佳的checkpoint。左侧的Smoothing滑动按钮可以调整曲线的平滑度,当损失函数震荡较大时,将Smoothing调大有助于观察loss的整体变化趋势。
- add_image()& 用numpy.array()对PIL图片进行转换
# -*- codeing = utf-8 -*-
# @Time : 2024/6/17 11:15
# @Author : Scarlett
# @File : hello_tb.py
# @Software : PyCharm
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer1 = SummaryWriter('logs/x')
writer2 = SummaryWriter('logs/y')
img_path = "dataset/train/ants/275429470_b2d7d9290b.jpg"
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)
writer1.add_image("hello_image", img_array, 2, dataformats='HWC')
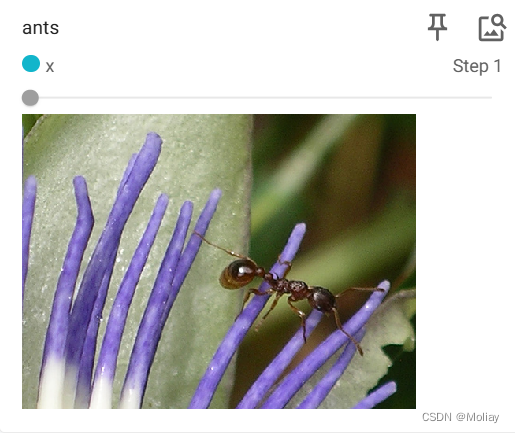
writer1.add_image("ants", img_array, 1, dataformats='HWC')
for i in range(10):
x = i
y = 2*i
writer1.add_scalar("f", x, i)
writer2.add_scalar("f", y, i)
writer1.close()
writer2.close()
通过滑块显示每一步的图形
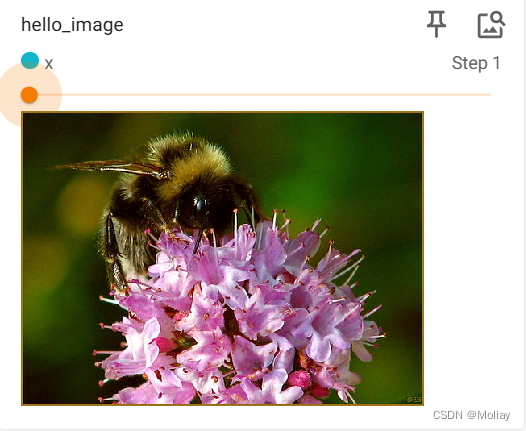
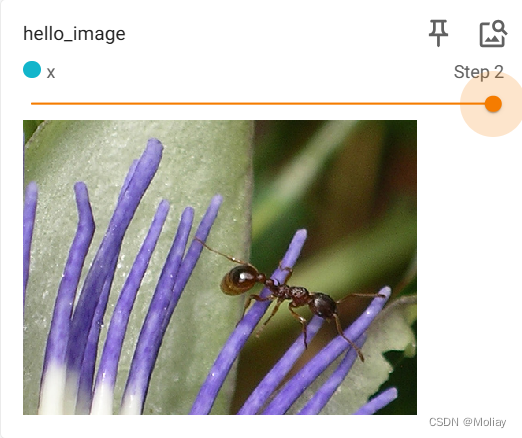
重命名title,以单独显示
tranforms图像预处理
从transforms中选择一个class,对它进行创建,对创建的对象传入图片,即可返回出结果
# -*- codeing = utf-8 -*-
# @Time : 2024/6/18 17:17
# @Author : Scarlett
# @File : hello_transforms1.py
# @Software : PyCharm
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path = "dataset/train/bees/39672681_1302d204d1.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
# how to use transforms
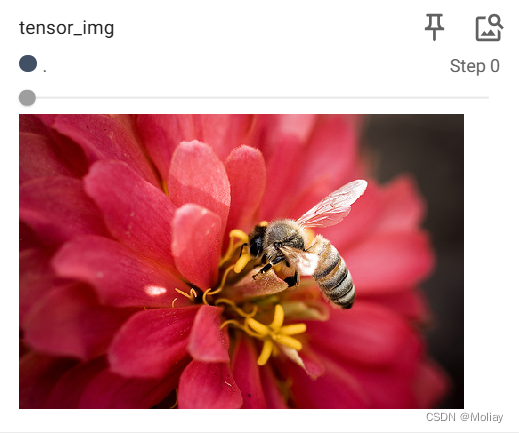
# ToTensor将一个 PIL Image 或 numpy.ndarray 转换为 tensor的数据类型
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image("tensor_img", tensor_img)
writer.close()
# -*- codeing = utf-8 -*-
# @Time : 2024/6/18 21:38
# @Author : Scarlett
# @File : use_transforms.py
# @Software : PyCharm
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/train/bees/586041248_3032e277a9.jpg")
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("totensor", img_tensor)
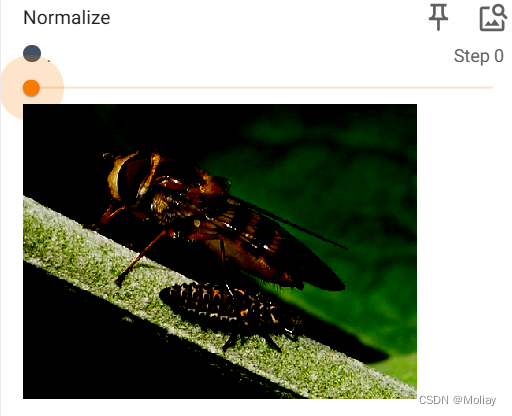
#nomalize
#用平均值/标准差归一化 tensor 类型的 image(输入)
#图片RGB三个信道,将每个信道中的输入进行归一化
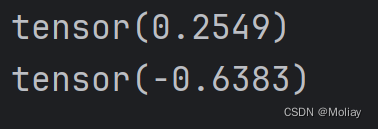
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([6, 3, 2],[9, 3, 5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 2)
writer.close()

PyCharm小技巧设置:忽略大小写,进行提示匹配
一般情况下,你需要输入R,才能提示出Resize。我们想设置,即便你输入的是r,也能提示出Resize,也就是忽略了大小写进行匹配提示:
File—> Settings—> 搜索case—> Editor-General-Code Completion-去掉Match case前的√—>Apply—>OK
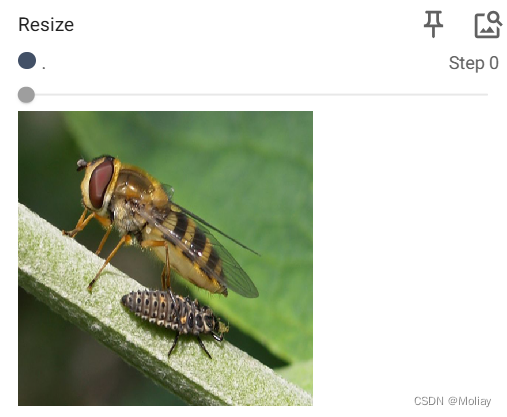
#resize
#将输入转变到指定尺寸:transforms.Resize((高度,宽度))
print(img.size)
trans_resize = transforms.Resize([512, 512])
img_resize = trans_resize(img_tensor)
writer.add_image("Resize", img_resize, 0)
print(img_resize)
#compose
#Compose() 中的参数需要是一个列表,Python中列表的表示形式为[数据1,数据2,...]
#在Compose中,数据需要是transforms类型,所以得到Compose([transforms参数1,transforms参数2,...])
trans_resize2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize2, trans_totensor])
img_resize2 = trans_compose(img)
writer.add_image("Compose",img_resize2, 1)

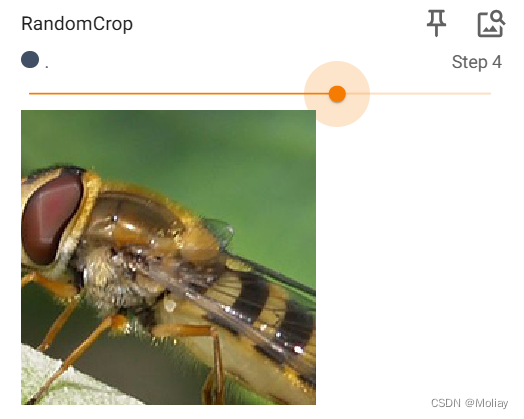
#RandomCrop
#随机裁剪
trans_random = transforms.RandomCrop(200)
trans_compose2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose2(img)
writer.add_image("RandomCrop", img_crop, i)
- 小结:
-
关注输入输出类型
-
多看官方文档
-
关注方法需要什么参数:参数如果设置了默认值,保留默认值即可,没有默认值的需要指定(看一下要求传入什么类型的参数)
-
不知道变量的输出类型可以通过
- 直接print该变量
- print(type()),看结果里显示什么类型
- 断点调试 dubug
-
totensor,在 tensorboard 看一下结果(tensorboard需要tensor数据类型进行显示)
-
torchvision中的数据集使用
CIFAR10 数据集包含了6万张32×32像素的彩色图片,图片有10个类别,每个类别有6千张图像,其中有5万张图像为训练图片,1万张为测试图片
# -*- codeing = utf-8 -*-
# @Time : 2024/6/19 11:27
# @Author : Scarlett
# @File : dataset_transforms.py
# @Software : PyCharm
import torchvision
from torch.utils.tensorboard import SummaryWriter
#把dataset_transform运用到数据集中的每一张图片,都转为tensor数据类型
#CIFAR10数据集原始图片是PIL Image,如果要给pytorch使用,需要转为tensor数据类型(转成tensor后,就可以用tensorboard了)
dataset_transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10('./data', train=True, transform=dataset_transforms, download=True)
test_set = torchvision.datasets.CIFAR10('./data', train=False, transform=dataset_transforms, download=True)
writer = SummaryWriter(log_dir='logs/logs1')
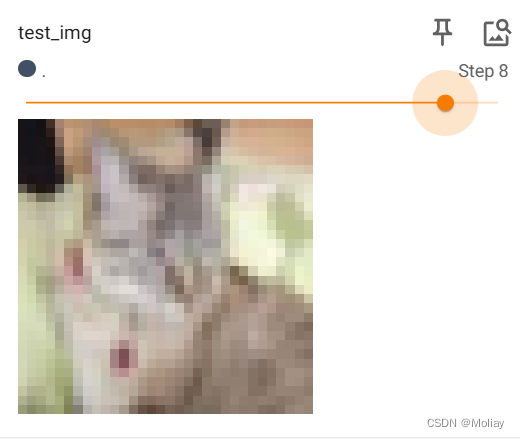
#显示测试数据集中的前10张图片
for i in range(10):
img, target = test_set[i]
writer.add_image('test_img', img, i)
writer.close()
DataLoader的使用
- Dataset:告诉程序中数据集的位置,数据集中索引,数据集 中有多少数据(一叠扑克牌)
- DataLoader:把数据加载到神经网络中,每次从Dataset中取数据,通过DataLoader中的参数可设置如何取数据(一组牌)
- 参数
- dataset:只有dataset没有默认值,只需把之前自定义的dataset实例化,再放到dataloader中即可
- batch_size:每组抓牌抓几张
- shuffle:是否打乱。默认为False即不打乱,但一般是指定为True
- num_workers:加载数据时采用单个进程还是多个进程,多进程的话速度相对较快,默认为0(主进程加载)。win系统下该值>0会有问题,报错BrokenPipeError
- drop_last:最后不足batch_size的余下是否舍去,不进行取出。例如10张牌每次抽取3张,最后余下1张,若drop_last为True代表舍去这张牌,不取出,否则为False代表不舍去,取出这张牌
# -*- codeing = utf-8 -*-
# @Time : 2024/6/19 14:54
# @Author : Scarlett
# @File : dataloader.py
# @Software : PyCharm
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备的测试数据集
test_data = torchvision.datasets.CIFAR10('./data', train=False, transform=torchvision.transforms.ToTensor())
#测试数据集中的第一张图片以及target
test_dataloader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("logs/dataloader")
step = 0
for data in test_dataloader:
imgs, targets = data
writer.add_images('dataloader', imgs, step)
step += 1
writer.close()

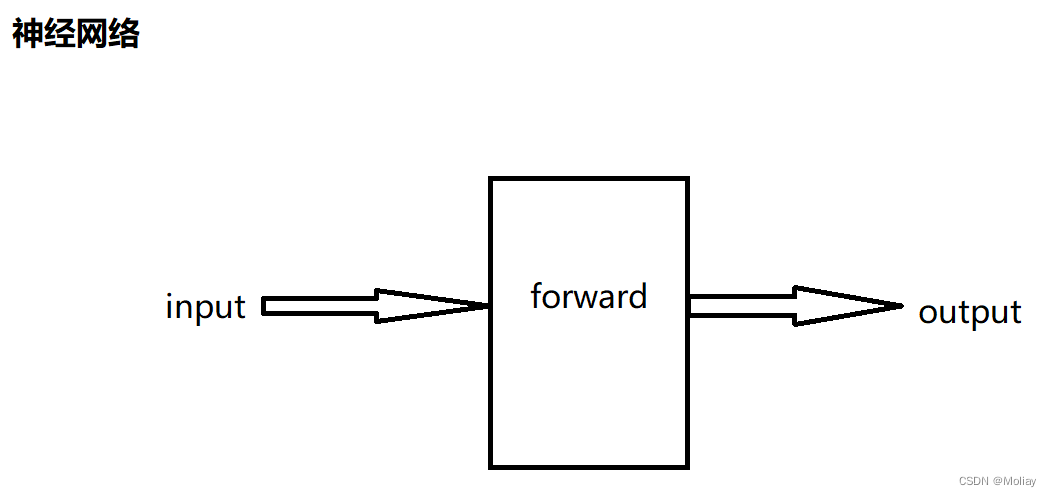
四、神经网络基础结构
神经网络的基本骨架
前向传播 forward(在所有子类中进行重写)
主要的大将

# -*- codeing = utf-8 -*-
# @Time : 2024/6/19 19:04
# @Author : Scarlett
# @File : nn_module.py
# @Software : PyCharm
import torch
from torch import nn
class Moli(nn.Module):
def __init__(self):
super().__init__()
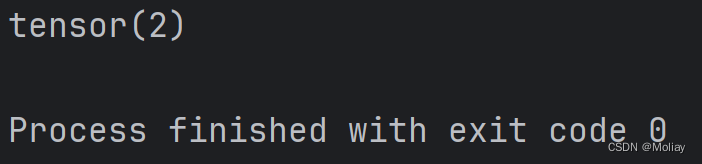
def forward(self, input):
return input + 1
moli = Moli()
x = torch.tensor(1)
print(moli(x))
卷积操作
# -*- codeing = utf-8 -*-
# @Time : 2024/6/19 21:37
# @Author : Scarlett
# @File : nn_conv.py
# @Software : PyCharm
import torch
import torch.nn.functional as F
input = torch.tensor([
[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]
])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
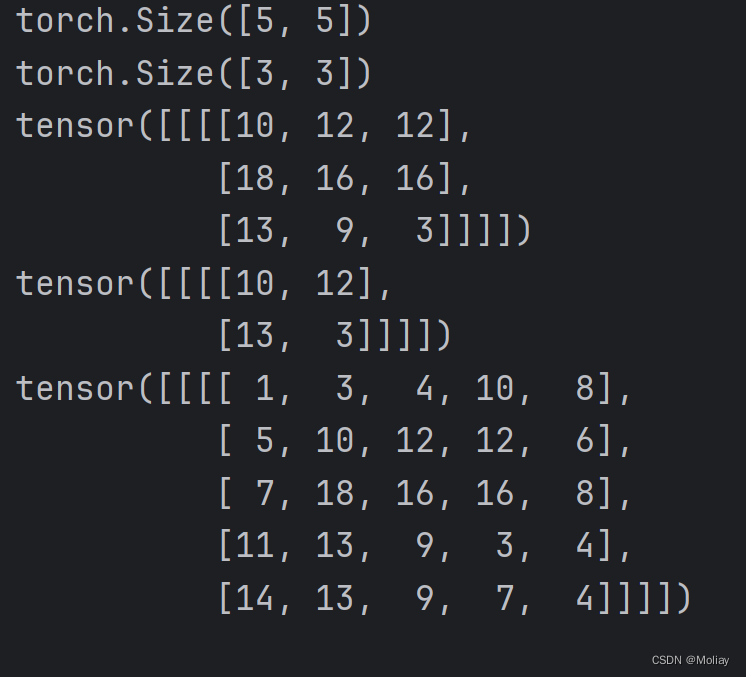
print(input.shape)
print(kernel.shape)
#(batch,通道数,高,宽)
input = input.reshape(1, 1, 5, 5)
kernel = torch.reshape(kernel, (1, 1, 3, 3))
#stride步长,可以是单个数,或元组(sH,sW) — 控制横向和纵向步长
output1 = F.conv2d(input, kernel, stride=1)
print(output1)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
#padding=1:将输入图像左右上下两边都拓展一个像素,空的地方默认为0
#在输入图像左右两边进行填充,决定填充有多大。可以为一个数或一个元组(分别指定高和宽,即纵向和横向每次填充的大小)。默认情况下不进行填充
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
神经网络-卷积层
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
# in_channels 输入图像的通道数
# out_channels 输出通道数
# kernel_size 卷积核大小
#以上参数需要设置
#以下参数提供了默认值
# stride=1 卷积过程中的步进大小
# padding=0 默认不进行填充
# dilation=1 每一个卷积核对应位的距离(空洞卷积,不常用)
# groups=1 一般设置为1,很少改动,改动的话为分组卷积
# bias=True 通常为True,对卷积后的结果是否加减一个常数的偏置
# padding_mode='zeros' 选择padding填充的模式

# -*- codeing = utf-8 -*-
# @Time : 2024/6/19 22:34
# @Author : Scarlett
# @File : nn_conv2d.py
# @Software : PyCharm
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10('./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(test_data, batch_size=64)
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3)
def forward(self, x):
return self.conv1(x)
moli = Moli()
print(moli)
writer = SummaryWriter('logs/logs2')
step = 0
for data in dataloader:
imgs, targets = data
output = moli(imgs)
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images('input_conv2d', imgs, step)
writer.add_images('output_conv2d', output, step)
step = step + 1
writer.close()
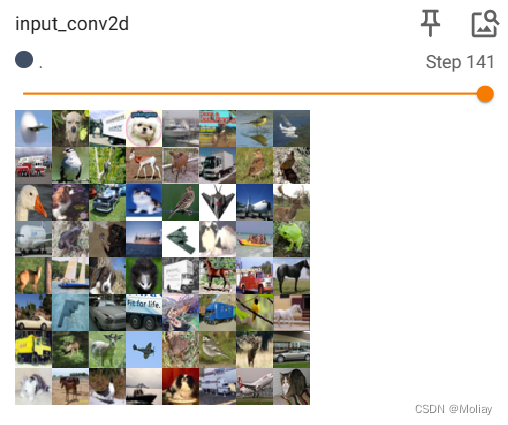
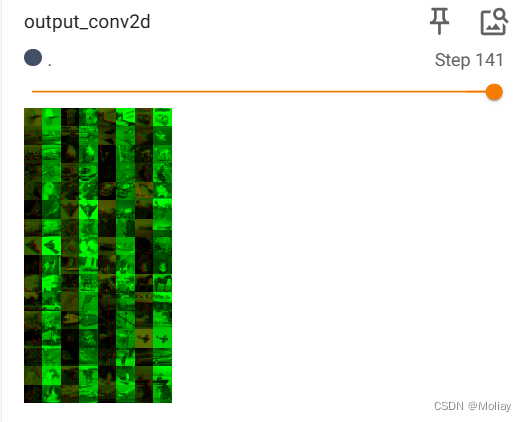
神经网络-最大池化的使用
# kernel_size 池化核
# 卷积中stride默认为1,而池化中stride默认为kernel_size
#ceil_mode是否向上取整,默认为false即向下取整
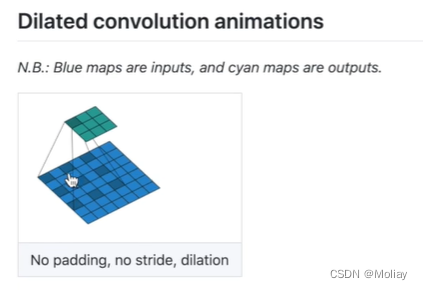
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0,
dilation=1, return_indices=False, ceil_mode=False)

dilation可以理解为膨胀~
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 10:53
# @Author : Scarlett
# @File : nn_maxpool.py
# @Software : PyCharm
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
#batch_size设为-1,即根据其他自动计算
input = torch.reshape(input, (-1, 1, 5, 5))
#搭建神经网络
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
# self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, x):
return self.maxpool1(x)
#创建神经网络
moli = Moli()
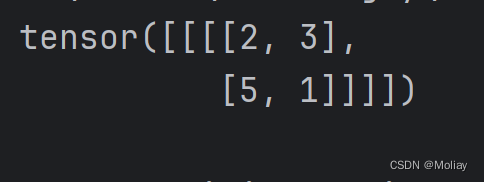
output = moli(input)
print(output)
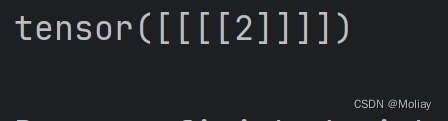
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 11:12
# @Author : Scarlett
# @File : nn_maxpool1.py
# @Software : PyCharm
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
#搭建神经网络
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
return self.maxpool1(input)
#创建神经网络
moli = Moli()
writer = SummaryWriter('logs/logs_maxpool')
step = 0
for data in dataloader:
imgs, targets = data
# output尺寸池化后不会有多个channel,原来是3维的图片
# 经过最大池化后还是3维的,不需要像卷积一样还要reshape操作(影响通道数的是卷积核个数)
output = moli(imgs)
writer.add_images('input_maxpool', imgs, step)
writer.add_images('output_maxpool', output, step)
step = step + 1
writer.close()
运行后在 terminal 里输入(注意是在pytorch环境下):



神经网络-非线性激活
- Padding Layers:对输入图像进行填充的各种方式
几乎用不到,nn.ZeroPad2d(在输入tensor数据类型周围用0填充)
nn.ConstantPad2d(用常数填充)
在 Conv2d 中可以实现,故不常用
ReLu
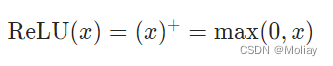
inplace:
是否替换,True替换,False不替换,默认为False
一般建议为False,能够保留原始数据

# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 12:04
# @Author : Scarlett
# @File : nn_relu.py
# @Software : PyCharm
import torch
from torch import nn
from torch.nn import ReLU
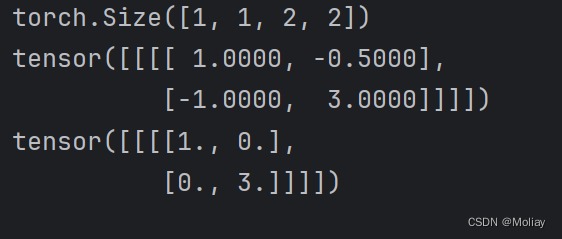
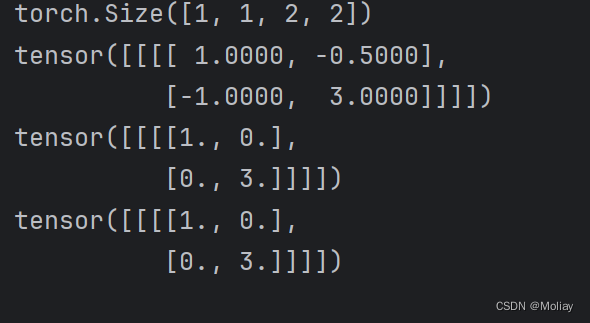
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
#搭建神经网络
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
#self.relu1 = ReLU()
self.relu1 = ReLU(inplace=True)
def forward(self, x):
return self.relu1(x)
#创建神经网络
moli = Moli()
print(input)
print(moli(input))
print(input)
跟输入对比可以看到:小于0的值被0截断,大于0的值仍然保留
Sigmoid
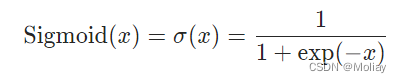
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 12:17
# @Author : Scarlett
# @File : nn_sigmoid.py
# @Software : PyCharm
import torchvision
from torch import nn
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
#搭建神经网络
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.sigmoid1 = Sigmoid()
def forward(self, input):
return self.sigmoid1(input)
#创建神经网络
moli = Moli()
writer = SummaryWriter('logs/logs_sigmoid')
step = 0
for data in dataloader:
imgs, targets = data
output = moli(imgs)
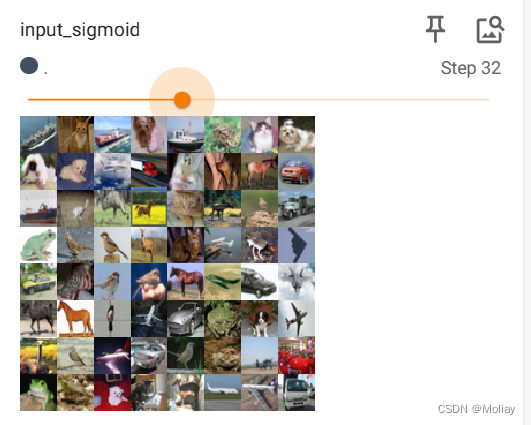
writer.add_images('input_sigmoid', imgs, step)
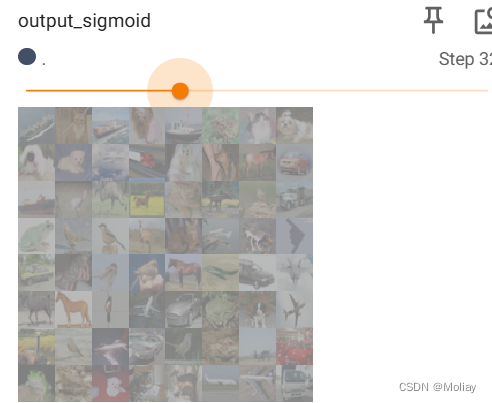
writer.add_images('output_sigmoid', output, step)
step += 1
writer.close()
神经网络-线性层及其他层介绍
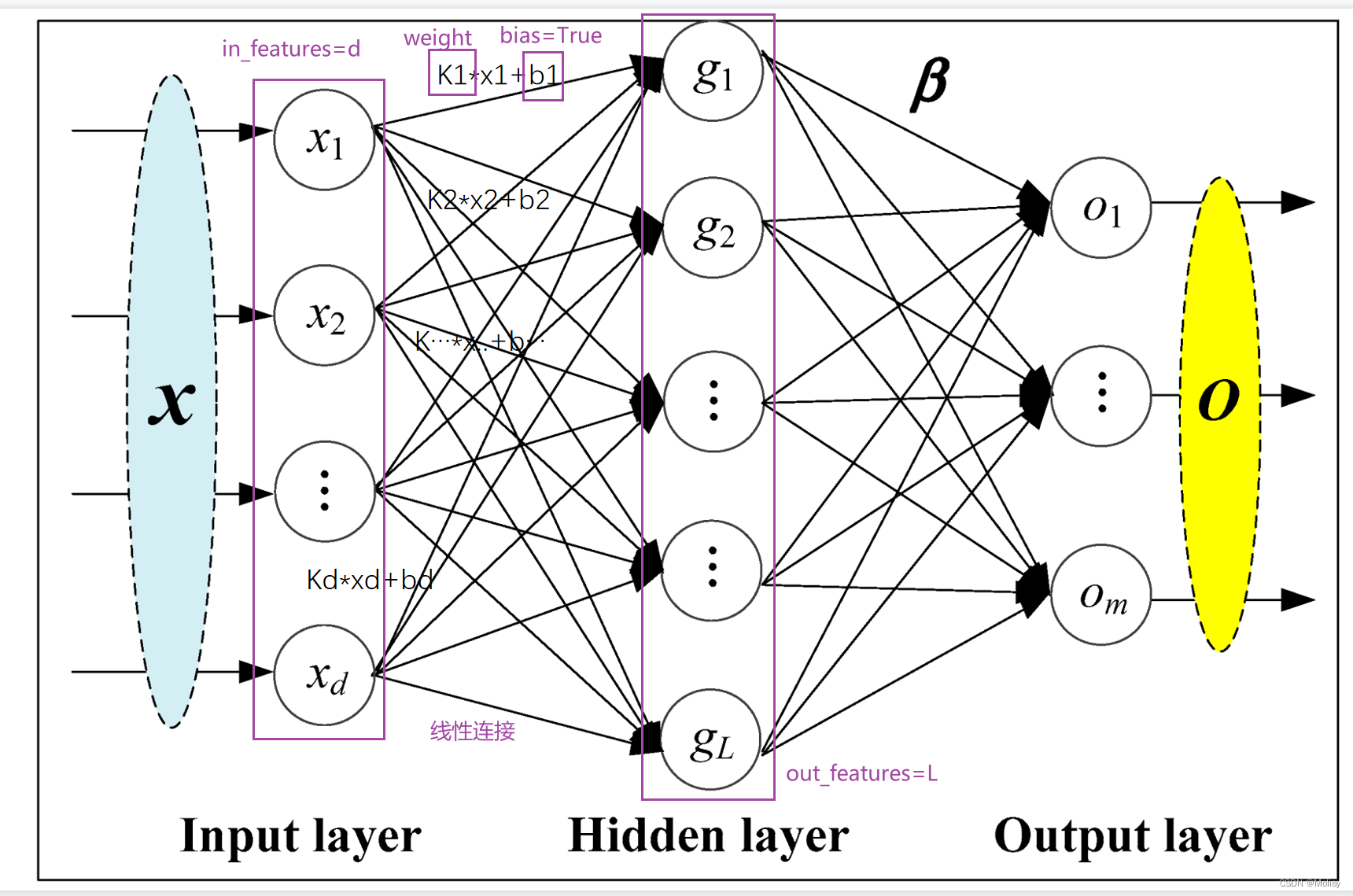
Linear
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 16:24
# @Author : Scarlett
# @File : nn_linear.py
# @Software : PyCharm
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10('./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, x):
return self.linear1(x)
for data in dataloader:
imgs, targets = data
# output = torch.reshape(imgs, (1, 1, 1, -1))
#flatten 摊平成一条
output = torch.flatten(imgs)
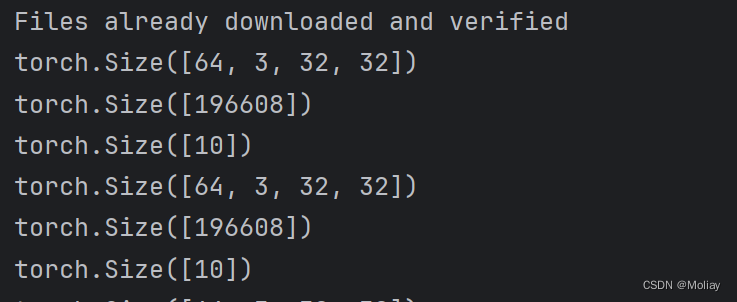
print(imgs.shape)
print(output.shape)
output = moli(output)
print(output.shape)
神经网络-搭建小实战和Sequential的使用
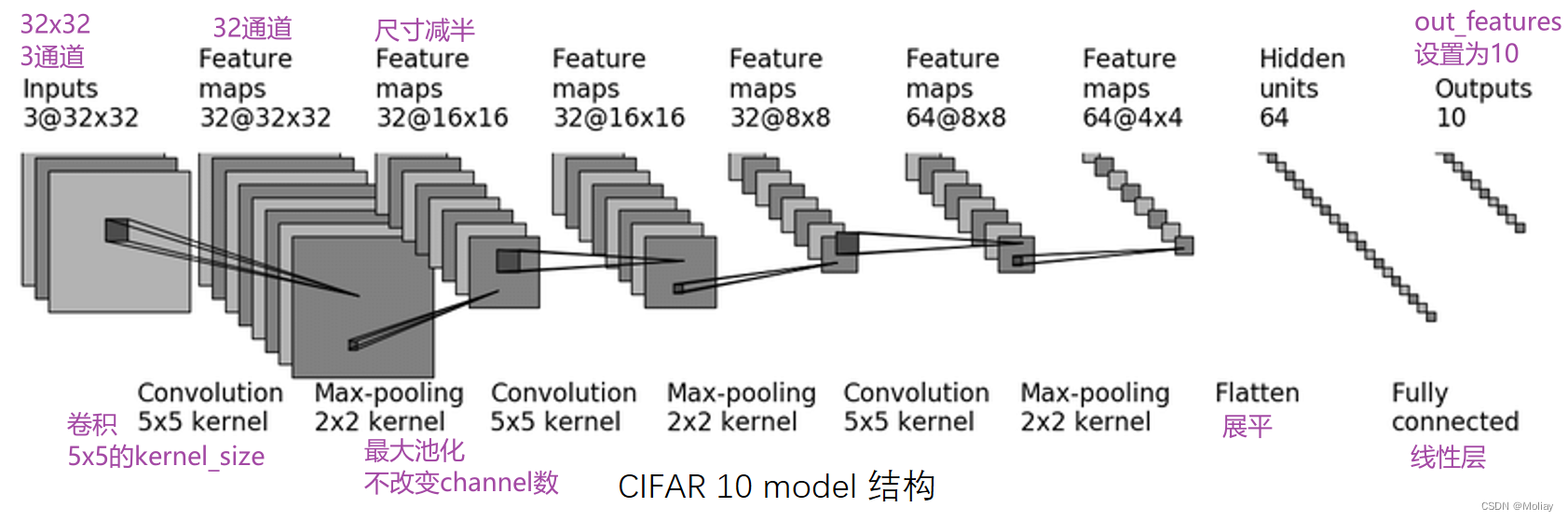
第一次卷积:首先加了几圈 padding(图像大小不变,还是32x32),然后卷积了32次
几个卷积核就是几通道的,一个卷积核作用于RGB三个通道后会把得到的三个矩阵的对应值相加,也就是说会合并,所以一个卷积核会产生一个通道
任何卷积核在设置padding的时候为保持输出尺寸不变都是卷积核大小的一半
通道变化时通过调整卷积核的个数(即输出通道)来实现的,在 nn.conv2d 的参数中有 out_channel 这个参数,就是对应输出通道
kernel 的内容是不一样的,可以理解为不同的特征抓取,因此一个核会产生一个channel

# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 17:32
# @Author : Scarlett
# @File : nn_sequential.py
# @Software : PyCharm
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
# class Moli(nn.Module):
# def __init__(self):
# super(Moli, self).__init__()
# self.conv1 = Conv2d(3, 32, 5, padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32, 32, 5, padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64)
# self.linear2 = Linear(64, 10)
#
# def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
# return x
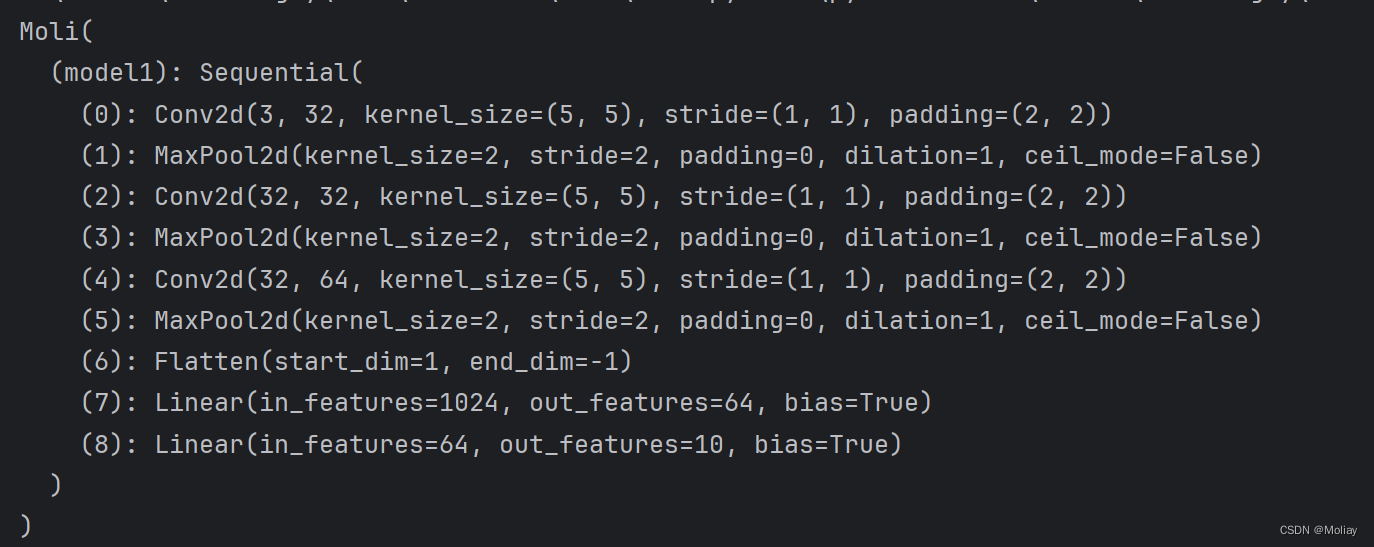
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
#用 Sequential 搭建,代码更简洁
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
moli = Moli()
print(moli)
#对网络结构进行检验
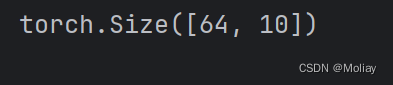
input = torch.ones((64, 3, 32, 32))
print(input)
output = moli(input)
print(output.shape)
writer = SummaryWriter('logs/logs_sequential')
writer.add_graph(moli, input)
writer.close()
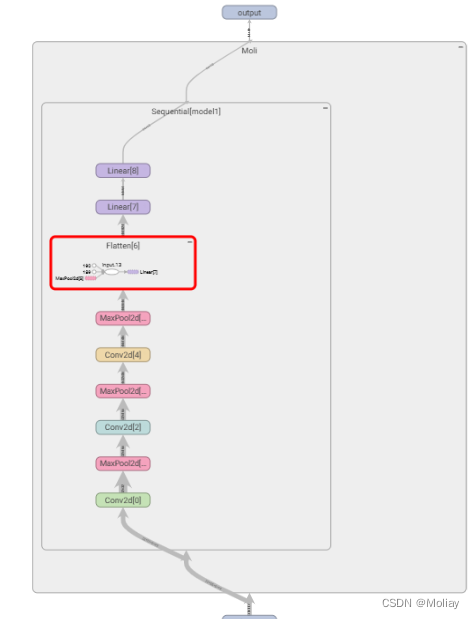
网络结构:
看到输出的维度是(64,1024),64可以理解为64张图片,1024就是flatten之后的维度了
双击矩形,可放大其中细节
五、pytorch常用模型
损失函数和反向传播
- torch.nn里的loss function衡量误差,在使用过程中根据需求使用,注意输入形状和输出形状
- loss衡量实际神经网络输出output和真实结果target的差距,越小越好
作用为:- 计算实际输出和目标之间的差距
- 为后续更新输出提供一定的依据(反向传播):给每一个卷积核中的参数提供了梯度grad,采用反向传播时,每一个要更新的参数都会计算出对应的梯度,优化过程中根据梯度对参数进行优化,最终达到整个loss进行降低的目的
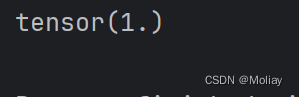
L1Loss

默认是取平均
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 20:22
# @Author : Scarlett
# @File : nn_loss.py
# @Software : PyCharm
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 2], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
print(loss(inputs, targets))
求和
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 20:22
# @Author : Scarlett
# @File : nn_loss.py
# @Software : PyCharm
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 2], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
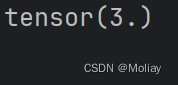
loss = L1Loss(reduction='sum')
print(loss(inputs, targets))
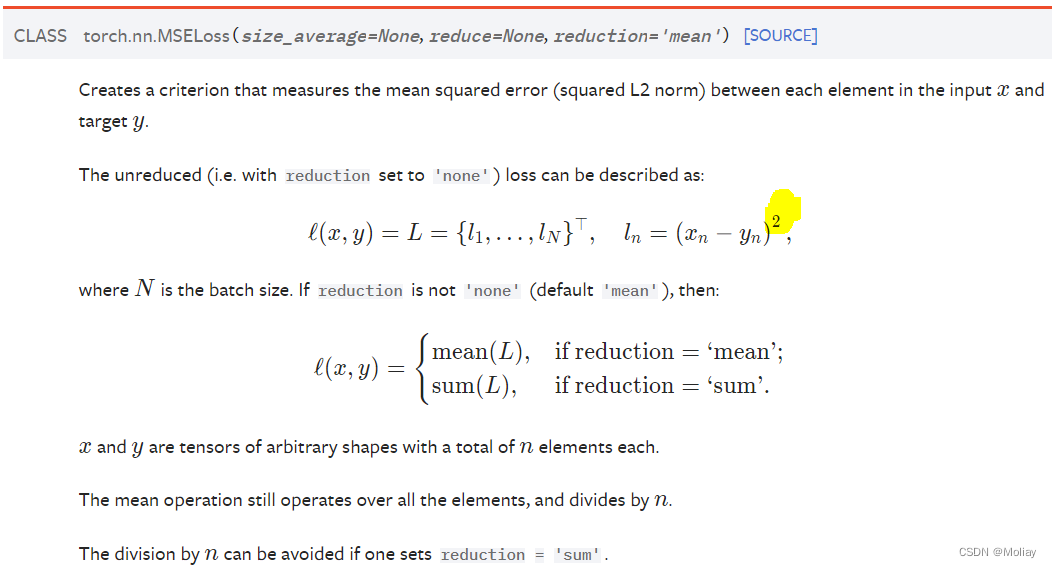
MSELoss均方误差
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 20:22
# @Author : Scarlett
# @File : nn_loss.py
# @Software : PyCharm
import torch
from torch.nn import MSELoss
inputs = torch.tensor([1, 2, 2], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = MSELoss()
print(loss(inputs, targets))
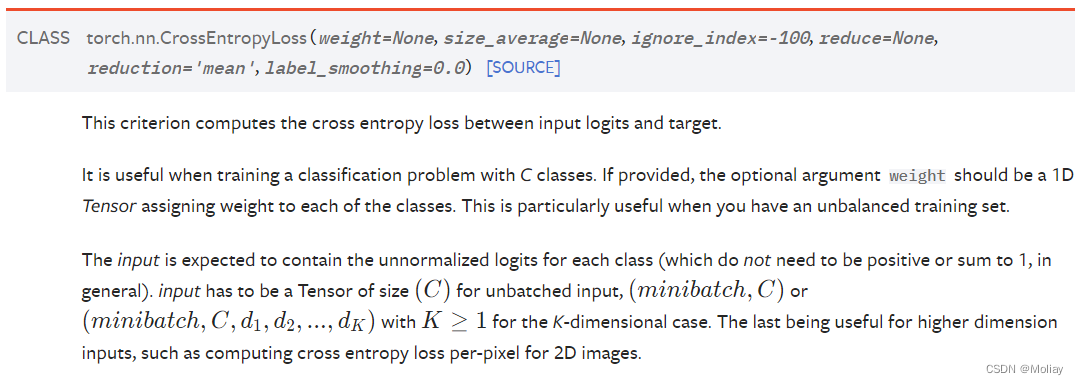
CrossEntropyLoss
适用于训练分类问题(C个类别)
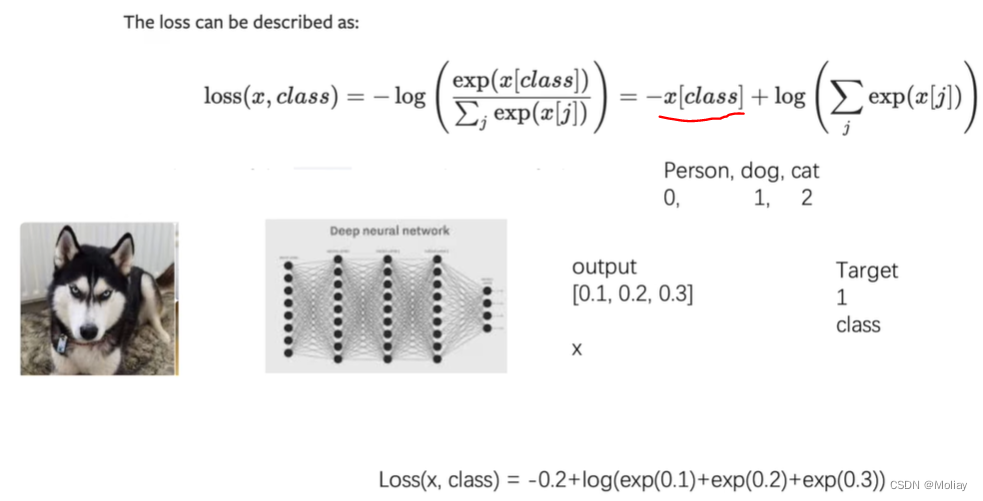

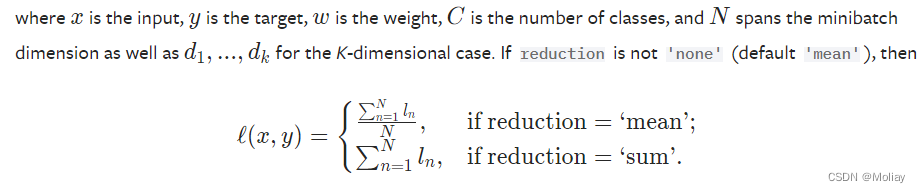
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 20:22
# @Author : Scarlett
# @File : nn_loss.py
# @Software : PyCharm
import torch
from torch import nn
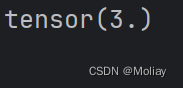
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
print(loss_cross(x, y))
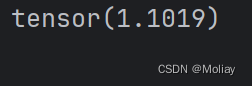
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 20:22
# @Author : Scarlett
# @File : nn_loss.py
# @Software : PyCharm
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
dataset = torchvision.datasets.CIFAR10('./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
moli = Moli()
loss = nn.CrossEntropyLoss()
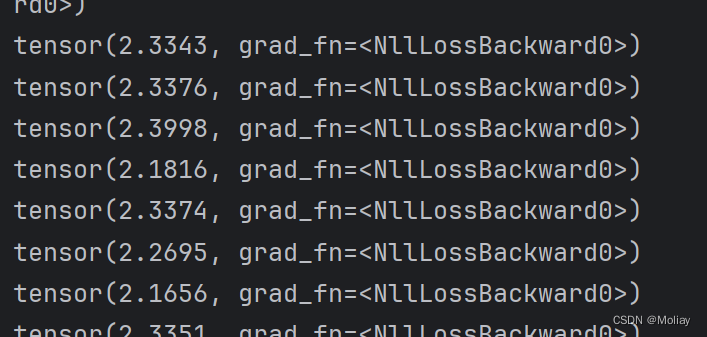
for data in dataloader:
imgs, targets = data
outputs = moli(imgs)
print(loss(outputs, targets))
优化器
optim
当使用损失函数时,可以调用损失函数的 backward,得到反向传播,反向传播可以求出每个需要调节的参数对应的梯度,有了梯度就可以利用优化器,优化器根据梯度对参数进行调整,以达到整体误差降低的目的
学习速率不能太大(太大模型训练不稳定)也不能太小(太小模型训练慢),一般建议先采用较大学习速率,后采用较小学习速率
#eg
#SGD : Stochastic Gradient Descent 随机梯度下降
#模型参数、学习速率、特定优化器算法中需要设定的参数
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
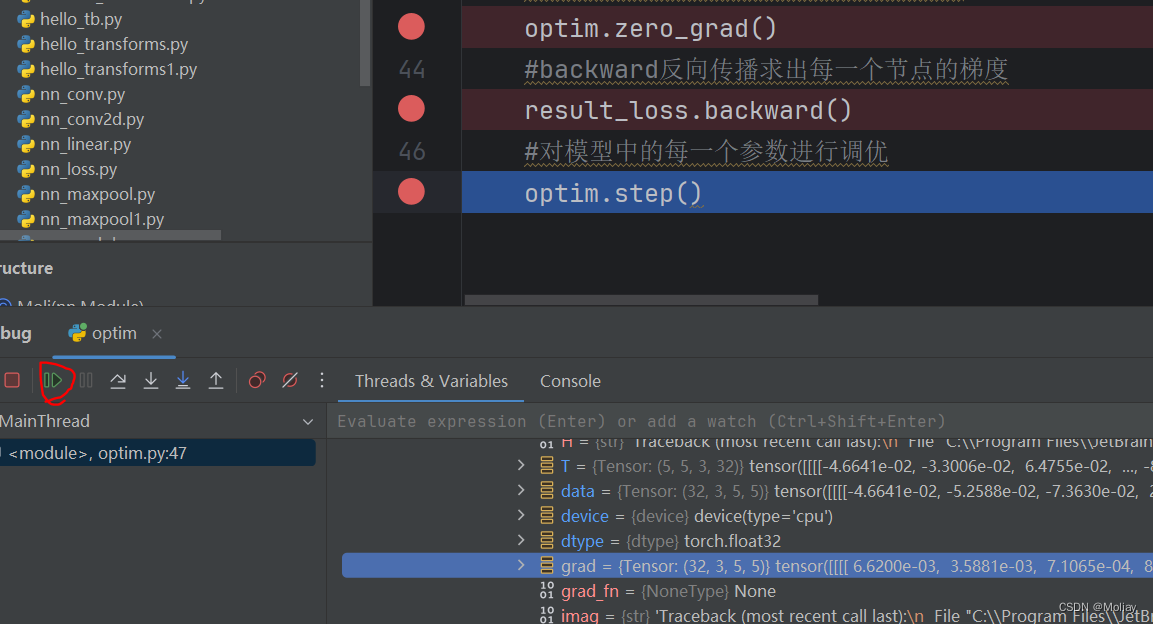
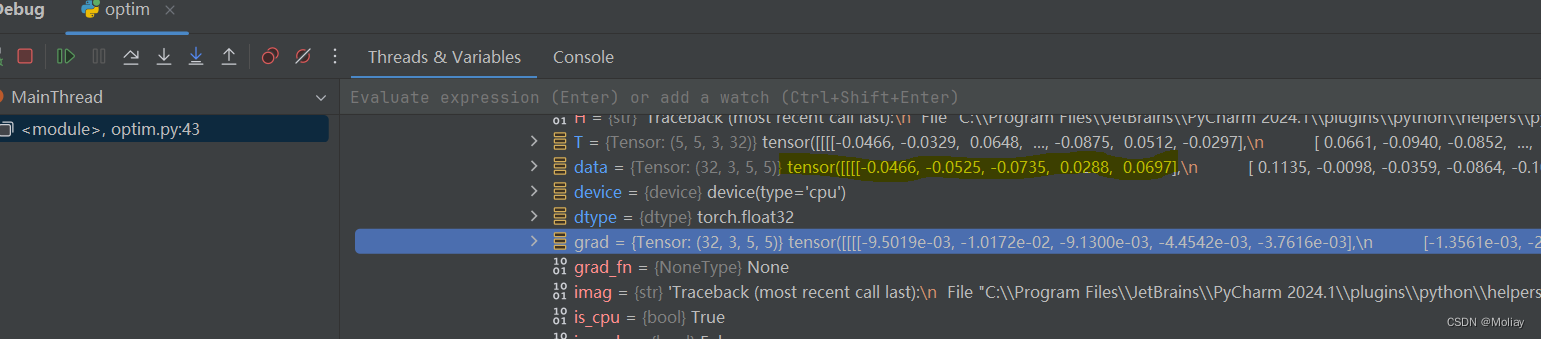
打断点并debug:
moli ——> Protected Attributes ——> _modules ——> ‘model1’ ——> Protected Attributes ——> _modules ——> ‘0’ ——> weight ——> data 或 grad
# -*- codeing = utf-8 -*-
# @Time : 2024/6/20 22:02
# @Author : Scarlett
# @File : optim.py
# @Software : PyCharm
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
dataset = torchvision.datasets.CIFAR10('./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
moli = Moli()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(moli.parameters(), lr=0.01)
#在 data 循环外又套一层 epoch 循环,一次 data 循环相当于对数据训练一次,加了 epoch 循环相当于对数据训练 10 次
for epoch in range(10):
#记录每轮的loss和
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = moli(imgs)
result_loss = loss(outputs, targets)
#对网络中的每一个参数的梯度进行清零
optim.zero_grad()
#backward反向传播求出每一个节点的梯度
result_loss.backward()
#对模型中的每一个参数进行调优
optim.step()
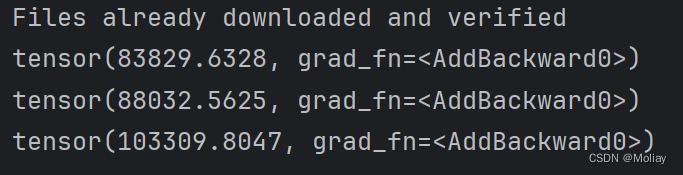
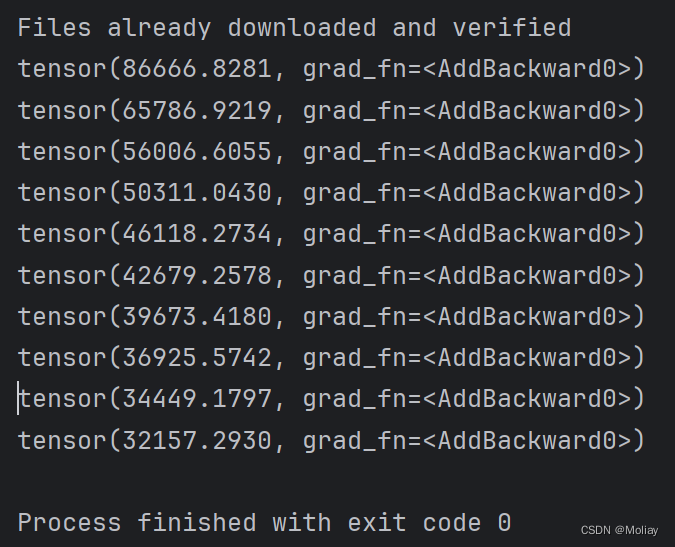
running_loss += result_loss
print(running_loss)
学习速率=0.01
学习速率=0.001
现有网络模型的使用和修改
在终端输入
pip list
查看是否有scipy,若无则需安装
pip install scipy
以vgg16网络架构为例
# -*- codeing = utf-8 -*-
# @Time : 2024/6/23 9:55
# @Author : Scarlett
# @File : model_pretrained.py
# @Software : PyCharm
import torchvision
vgg16_true = torchvision.models.vgg16(pretrained=True)
vgg16_false = torchvision.models.vgg16(pretrained=False)
print(vgg16_true)
输出内容:
VGG(
(features): Sequential(
# 输入图片经过卷积,输入是3通道,输出是64通道,卷积核是3*3
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# 非线性
(1): ReLU(inplace=True)
# 卷积
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# 非线性
(3): ReLU(inplace=True)
# 池化
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
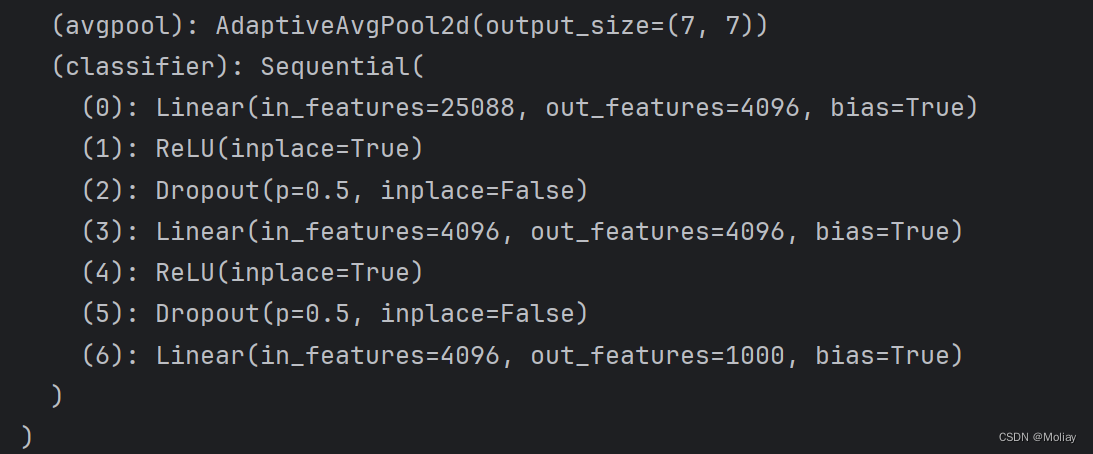
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
# 线性输出层为1000(vgg16是一个分类模型,能分出1000个类别)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
- 添加
import torchvision
from torch import nn
vgg16_true = torchvision.models.vgg16(pretrained=True)
vgg16_false = torchvision.models.vgg16(pretrained=False)
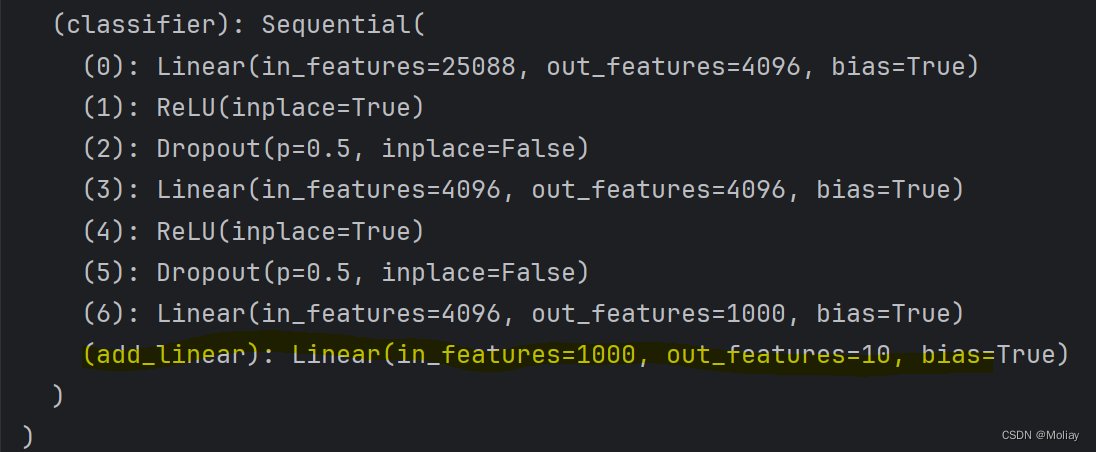
vgg16_true.add_module('add_linear', nn.Linear(in_features=1000, out_features=10))
print(vgg16_true)
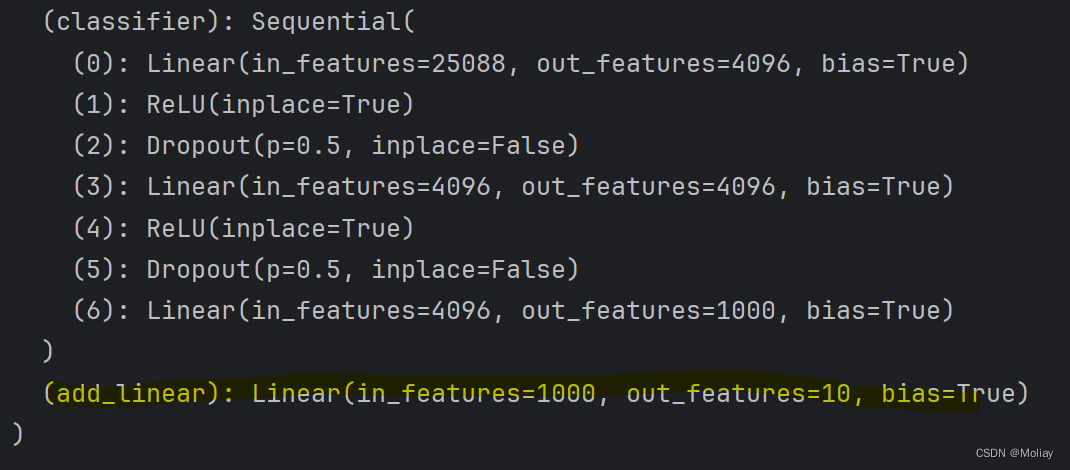
把module添加到classifier中
import torchvision
from torch import nn
vgg16_true = torchvision.models.vgg16(pretrained=True)
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true.classifier.add_module('add_linear', nn.Linear(in_features=1000, out_features=10))
print(vgg16_true)
- 修改
import torchvision
from torch import nn
vgg16_true = torchvision.models.vgg16(pretrained=True)
vgg16_false = torchvision.models.vgg16(pretrained=False)
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
网络模型的保存与读取
- 保存方式1,能够保存模型结构和模型参数
import torch
from torchvision import models
vgg16 = models.vgg16(pretrained=True)
# 保存方式1,能够保存模型结构和模型参数
torch.save(vgg16, "vgg16_method1.pth")
但需要注意的是,用该方式保存的话,加载时要让程序能够其模型定义。
反例:
# -*- codeing = utf-8 -*-
# @Time : 2024/7/1 14:40
# @Author : Scarlett
# @File : model_save.py
# @Software : PyCharm
import torch
from torch import nn
from torchvision import models
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3)
def forward(self, x):
return self.conv1(x)
moli = Moli()
torch.save(moli, "moli_method1.pth")
# -*- codeing = utf-8 -*-
# @Time : 2024/7/1 14:46
# @Author : Scarlett
# @File : model_load.py
# @Software : PyCharm
import torch
import torchvision
model = torch.load("moli_method1.pth")
不能得到’Moli’这个属性,因为没有这个类

解决:需要将 model_save.py 中的网络结构复制到 model_load.py 中(为了确保加载的网络模型是想要的网络模型)
# -*- codeing = utf-8 -*-
# @Time : 2024/7/1 14:46
# @Author : Scarlett
# @File : model_load.py
# @Software : PyCharm
import torch
import torchvision
from torch import nn
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3)
def forward(self, x):
return self.conv1(x)
model = torch.load("moli_method1.pth")
print(model)

实际写项目过程中,往往直接定义在一个单独的文件中(如model_save.py),再在 model_load.py 中:
from model_save import *
- (官方推荐)保存方式2,能够保存模型参数
# 保存方式2,把vgg16的状态保存为字典形式
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
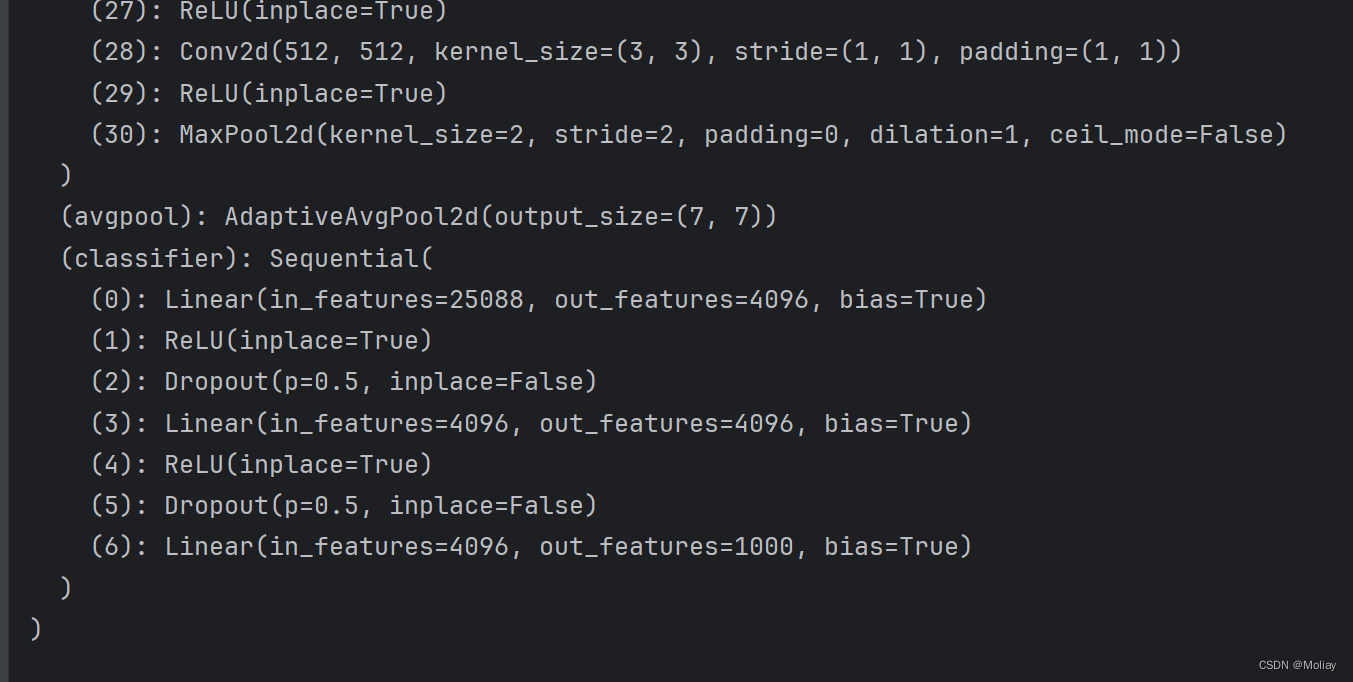
- 加载方式1,打印的网络模型结构
import torch
# 对应保存方式1,打印出的是网络模型的结构
model = torch.load("vgg16_method1.pth")
print(model) # 打印的只有模型结构,但其实参数也保存起来了
- 加载方式2,打印的是参数的字典形式
# 方式2,加载模型
model = torch.load("vgg16_method2.pth")
print(model)
恢复网络模型结构
# 方式2,加载模型
vgg16 = torchvision.models.vgg16(pretrained=True)
#以数据字典的形式加载参数
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
完整的模型训练套路
# -*- codeing = utf-8 -*-
# @Time : 2024/7/1 17:17
# @Author : Scarlett
# @File : train.py
# @Software : PyCharm
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
train_data = torchvision.datasets.CIFAR10('./data', train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10('./data', train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("Train data size: {}".format(train_data_size)) #Train data size: 50000
print("Test data size:", test_data_size) #Test data size: 10000
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, 64)
test_dataloader = DataLoader(test_data, 64)
# 创建网络模型
moli = Moli()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.001
optimizer = torch.optim.SGD(moli.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter('logs/log_train')
for i in range(epoch):
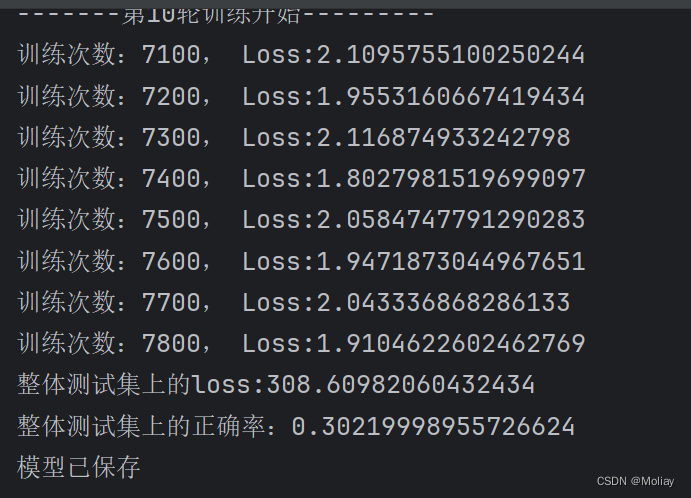
print("-------第{}轮训练开始---------".format(i + 1))
# 训练步骤开始
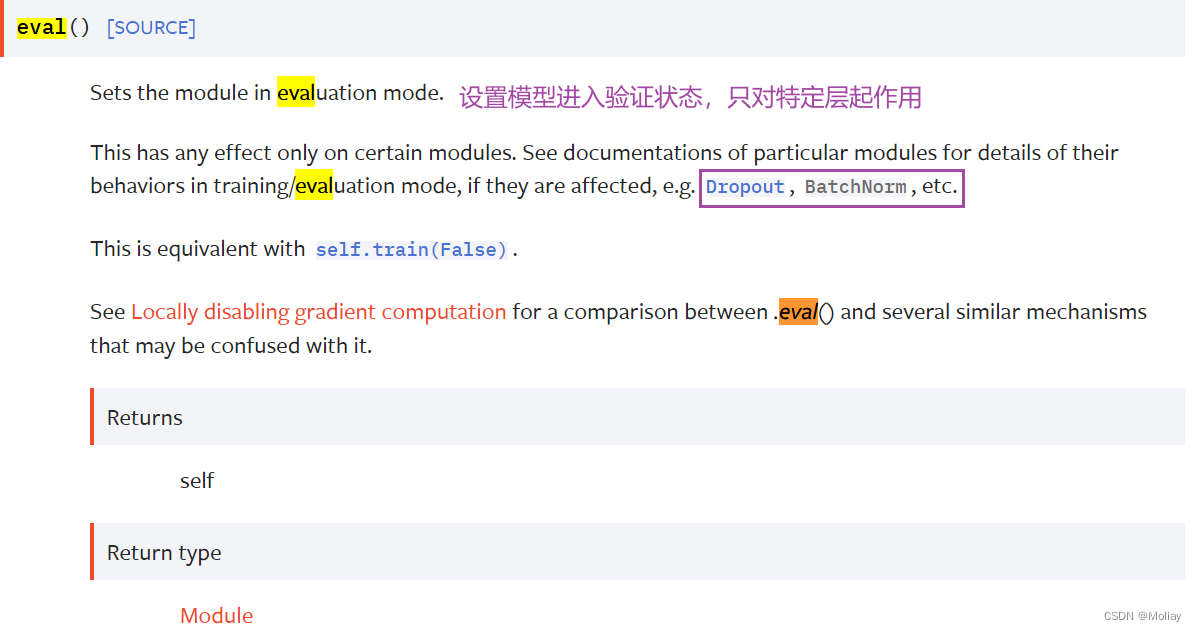
moli.train() #让你的模型知道现在正在训练。像 dropout、batchnorm 层在训练和测试时的作用不同,所以需要使它们运行在对应的模式中
for data in train_dataloader:
imgs, targets = data
output = moli(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
moli.eval() #设置模型为评估/推理模式,等效于 model.train(False)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): #测试时无需用梯度进行调整优化
for data in test_dataloader:
imgs, targets = data
output = moli(imgs)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
accuracy = (output.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(moli, 'moli_{}.pth'.format(i))
# torch.save(moli.state_dict(), 'moli_{}.pth'.format(i))
print('模型已保存')
writer.close()
# -*- codeing = utf-8 -*-
# @Time : 2024/7/1 17:36
# @Author : Scarlett
# @File : model.py
# @Software : PyCharm
import torch
from torch import nn
# 搭建神经网络
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
#如果模块是被直接运行的,则代码块被运行,如果模块被import,则代码块不被运行
if __name__ == '__main__':
moli = Moli()
input = torch.ones(64, 3, 32, 32)
output = moli(input)
print(output.size())
利用GPU训练
有两种方式(第2张更常用)
- 方式1

网络模型
moli = Moli()
if torch.cuda.is_available():
moli = moli.cuda() # 把网络模型转移到cuda上
损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可用交叉熵
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
数据(输入、标注)
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
完整代码:
# -*- codeing = utf-8 -*-
# @Time : 2024/7/1 17:17
# @Author : Scarlett
# @File : train.py
# @Software : PyCharm
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
train_data = torchvision.datasets.CIFAR10('./data', train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10('./data', train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("Train data size: {}".format(train_data_size)) #Train data size: 50000
print("Test data size:", test_data_size) #Test data size: 10000
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, 64)
test_dataloader = DataLoader(test_data, 64)
# 搭建神经网络
class Moli(nn.Module):
def __init__(self):
super(Moli, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 创建网络模型
moli = Moli()
if torch.cuda.is_available():
moli = moli.cuda() # 把网络模型转移到cuda上
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可用交叉熵
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 优化器
learning_rate = 0.001
optimizer = torch.optim.SGD(moli.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter('logs/log_train')
for i in range(epoch):
print("-------第{}轮训练开始---------".format(i + 1))
# 训练步骤开始
moli.train() #让你的模型知道现在正在训练。像 dropout、batchnorm 层在训练和测试时的作用不同,所以需要使它们运行在对应的模式中
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
output = moli(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
moli.eval() #设置模型为评估/推理模式,等效于 model.train(False)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): #测试时无需用梯度进行调整优化
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
output = moli(imgs)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
accuracy = (output.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(moli, 'moli_{}.pth'.format(i))
# torch.save(moli.state_dict(), 'moli_{}.pth'.format(i))
print('模型已保存')
writer.close()
- 方式2(更常用)

以下两种写法对于单显卡来说等价:
torch.device('cuda')
torch.device('cuda:0')
网络模型和损失函数是否再次赋值都可以
loss_fn = loss_fn.to(device)
或者
loss_fn.to(device)
数据(图片、标注)需要另外转移之后再重新赋值给变量
imgs = imgs.to(device)
targets = targets.to(device)
完整程序示例
# -*- codeing = utf-8 -*-
# @Time : 2024/7/1 17:17
# @Author : Scarlett
# @File : train.py
# @Software : PyCharm
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
# 定义训练的设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 准备数据集
train_data = torchvision.datasets.CIFAR10('./data', train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10('./data', train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("Train data size: {}".format(train_data_size)) #Train data size: 50000
print("Test data size:", test_data_size) #Test data size: 10000
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, 64)
test_dataloader = DataLoader(test_data, 64)
# 创建网络模型
moli = Moli()
# moli = moli.to(device)
moli.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
#loss_fn = loss_fn.to(device)
loss_fn.to(device)
# 优化器
learning_rate = 0.001
optimizer = torch.optim.SGD(moli.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter('logs/log_train')
for i in range(epoch):
print("-------第{}轮训练开始---------".format(i + 1))
# 训练步骤开始
moli.train() #让你的模型知道现在正在训练。像 dropout、batchnorm 层在训练和测试时的作用不同,所以需要使它们运行在对应的模式中
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = moli(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
moli.eval() #设置模型为评估/推理模式,等效于 model.train(False)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): #测试时无需用梯度进行调整优化
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = moli(imgs)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
accuracy = (output.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(moli, 'moli_{}.pth'.format(i))
# torch.save(moli.state_dict(), 'moli_{}.pth'.format(i))
print('模型已保存')
writer.close()
完整的模型验证套路
利用已经训练好的模型,给它提供输入进行测试(类似之前案例中测试集的测试部分)
# -*- codeing = utf-8 -*-
# @Time : 2024/7/2 12:26
# @Author : Scarlett
# @File : test.py
# @Software : PyCharm
from PIL import Image
from torchvision import transforms
from train import *
img_path = "imgs/dog.PNG"
image = Image.open(img_path)
print(image)
# 因为png格式是四通道,除了RGB三通道外,还有一个透明度通道,所以要调用上述语句保留其颜色通道
# 当然,如果图片本来就是三颜色通道,经过此操作,不变
# 加上这一步后,可以适应 png jpg 各种格式的图片
image = image.convert('RGB')
transform = transforms.Compose([transforms.Resize((32, 32)),
transforms.ToTensor()])
image = transform(image)
print(image.shape)
model = torch.load('moli_0.pth', map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
开源项目